Velocity Model Building From Raw Shot Gathers Using Machine Learning
Interpreting seismic data is essential in industries such as oil and gas exploration, environmental research, and geotechnical engineering. One of the core aspects of seismic interpretation is constructing accurate velocity models, which outline how seismic waves travel through the Earth’s layers. Traditionally, creating these models involved time-consuming manual analysis, but with the advent of machine learning, this process has become significantly more precise, efficient, and scalable. This article delves into how machine learning can transform the creation of velocity models from raw shot gathers.
Understanding Raw Shot Gathers
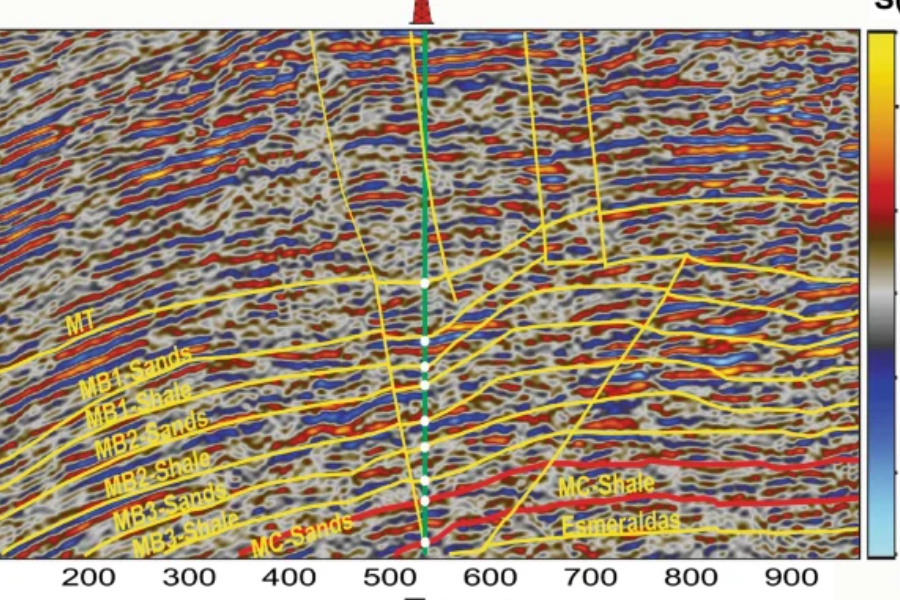
In seismic surveys, a shot gather refers to the collection of data captured by geophones following a seismic event, known as a “shot,” which is triggered at a specific location. While these shot gathers contain valuable information, they are often noisy and require considerable cleaning and preprocessing before they can be analyzed effectively. Machine learning plays a vital role in automating and refining this initial stage, drastically improving the accuracy and speed of processing.

The Importance of Velocity Models in Seismic Data Interpretation
Velocity model building from raw shot gathers using machine learning are fundamental to seismic data interpretation, playing a central role in understanding the Earth’s subsurface. These models describe how seismic waves travel through various geological layers, providing vital information about the subsurface’s structure and composition. An accurate velocity model is essential for producing precise seismic images, which in turn inform a wide range of decisions in industries such as oil and gas exploration, environmental studies, and earthquake assessment.
Understanding Seismic Wave Propagation
Seismic waves, generated by a seismic source such as an explosion or a vibratory truck, travel through the Earth’s layers at different speeds depending on the type of material they encounter. The velocity at which these waves propagate is influenced by factors such as the rock type, porosity, and fluid content. By constructing velocity models, geophysicists can better understand the distribution of these materials at various depths and map out the Earth’s internal structures with greater accuracy.
Identifying Subsurface Features
Velocity models are key tools for identifying subsurface features such as rock formations, fault zones, and fluid reservoirs. For example, certain rock types may have higher or lower seismic wave velocities, allowing geophysicists to differentiate between sedimentary, igneous, or metamorphic rocks. Similarly, the presence of fluids such as water, oil, or gas can alter the velocity of seismic waves, helping to pinpoint potential reservoirs. These models enable the accurate identification of valuable geological resources and provide critical insights into the subsurface environment.
Enhancing Seismic Imaging
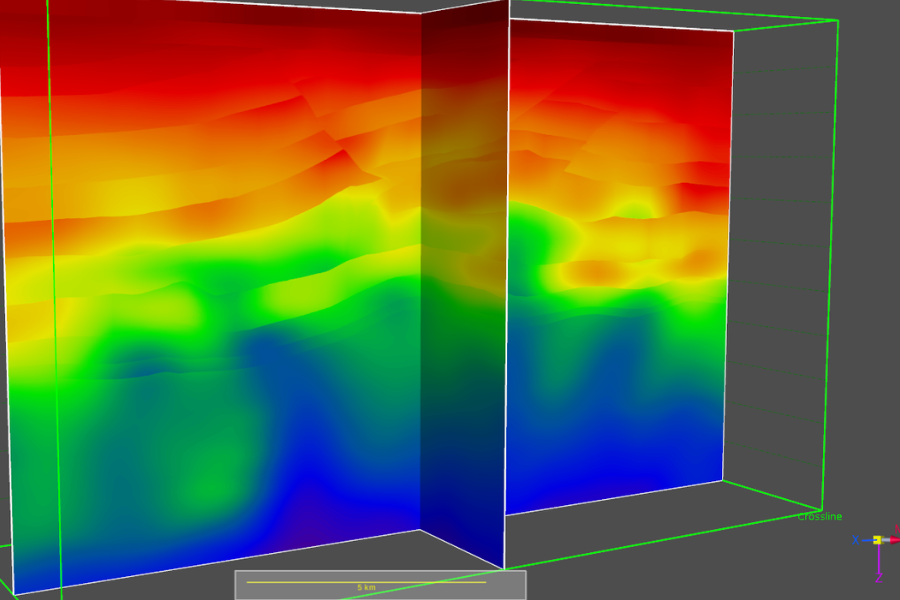
Seismic imaging involves using seismic waves to create detailed maps of subsurface structures. An accurate velocity model is essential for the inversion process, where raw seismic data is converted into clear images of the Earth’s interior. Velocity models help correct for the effects of varying wave speeds across different layers, ensuring that the seismic images produced are true representations of subsurface geology. Without accurate velocity models, the resulting seismic images could be distorted, leading to misinterpretations.
Applications in Natural Resource Exploration
In oil and gas exploration, velocity models are used to determine the location of potential reservoirs. By understanding how seismic waves move through different rock types and identifying anomalies in wave propagation, geophysicists can predict the presence of hydrocarbons beneath the Earth’s surface. Accurate velocity models help guide drilling operations, minimizing the risk of costly mistakes and ensuring that drilling efforts target the most promising sites.
Earthquake Hazard Assessment
Velocity models also play a critical role in assessing earthquake hazards. By understanding how seismic waves travel through different regions, scientists can predict how earthquakes might propagate across the Earth’s surface. This information is crucial for determining earthquake-prone areas and for designing structures that can withstand seismic activity. Accurate velocity models help assess ground shaking, making it possible to estimate the impact of an earthquake on infrastructure and populations.
Guiding Drilling Decisions
In the context of geotechnical engineering and mining, velocity models help guide drilling and excavation activities. By providing a detailed map of the subsurface, these models allow engineers to identify safe drilling locations, avoid hazardous zones, and optimize resource extraction. Inaccurate velocity models could lead to drilling in unsuitable locations, increasing costs and the risk of failure.
Minimizing Errors in Subsurface Interpretation
The process of creating velocity models is complex, and errors in these models can have significant consequences. Misinterpreting seismic data or inaccuracies in velocity calculations can result in wrong conclusions about the subsurface, potentially leading to costly mistakes. These errors could affect decisions regarding resource extraction, earthquake preparedness, or infrastructure development. Therefore, geophysicists prioritize improving the accuracy and efficiency of velocity model building from raw shot gathers using machine learning, especially with the help of advanced technologies like machine learning and data-driven approaches.
Traditional Approaches to velocity model building from raw shot gathers using machine learning
Historically, building velocity models involved a manual and iterative process, requiring expert knowledge to interpret seismic data. While effective, these methods are slow and can be prone to human error, especially when working with large datasets from modern seismic surveys. This traditional approach is becoming increasingly inefficient, driving the need for automation through machine learning.
Overcoming Challenges in velocity model building from raw shot gathers using machine learning
Velocity model construction presents several challenges, particularly because seismic data is often noisy and complex. Additionally, the inversion process needed to derive velocity models from seismic data can be computationally expensive and highly sensitive—minor changes in the data can lead to significant variations in the resulting model. Another obstacle is the subjective nature of manual interpretation, as different experts may draw differing conclusions from the same data. These challenges highlight the potential benefits of machine learning in automating and enhancing velocity model generation.
Machine Learning: A Modern Solution for velocity model building from raw shot gathers using machine learning
Machine learning provides an efficient way to address these challenges. By training algorithms on large sets of seismic data, machine learning models can detect patterns that align with specific geological features, enabling the automation of tasks traditionally done by human experts, such as identifying layer boundaries and estimating seismic velocities. Machine learning also improves the speed at which data can be processed, making it possible to handle larger datasets and generate more accurate models in less time.
Types of Machine Learning Techniques for Seismic Data
Various machine learning approaches are being used in seismic data processing, each serving different purposes. Supervised learning is commonly used, where models are trained on labeled datasets to predict the velocity models for new, unseen shot gathers. Unsupervised learning doesn’t require labeled data and can cluster seismic data into groups based on similarities, aiding in the discovery of previously unnoticed patterns. Another promising technique is reinforcement learning, where models learn by receiving feedback from interactions with the data.
Steps to Build a Velocity Model from Raw Shot Gathers Using Machine Learning
Creating a velocity model from raw seismic data involves several stages. Initially, the raw shot gather data undergoes preprocessing to remove noise and correct distortions from the Earth’s surface. Then, feature extraction is performed, focusing on key attributes such as travel time, amplitude, and frequency, which provide insights into subsurface structures.
After feature extraction, a machine learning model is trained on a set of labeled shot gathers, where the velocity model is known. Once the model has been trained, it can predict the velocity models for new, unlabeled shot gathers. These predictions are validated against known datasets or compared to results obtained through traditional methods to ensure their accuracy.
Preprocessing Data for Machine Learning
Before machine learning can be applied to seismic data, preprocessing is essential. Raw shot gathers are often plagued by noise caused by environmental factors, equipment, or surface waves, which can obscure the useful data. Effective preprocessing ensures that the data is clean and normalized, making it suitable for machine learning analysis.
Extracting Features from Shot Gathers
In seismic data processing, feature engineering involves calculating attributes like frequency, phase, and envelope amplitude from the raw shot gathers. These features provide essential information about the subsurface and assist the machine learning model in distinguishing between different geological formations. Additionally, techniques such as Principal Component Analysis (PCA) can be used to reduce the complexity of the data without losing important information, allowing machine learning models to operate more efficiently.
Labeling Training Data for Machine Learning Models
In supervised machine learning, the quality and accuracy of the training data play a crucial role in the success of the model. Labeling the training data correctly is an essential step, as it allows the model to learn the relationships between input data (such as raw shot gathers) and the corresponding output (velocity models). In the case of seismic data, this process involves associating each shot gather with a known velocity model, which serves as the “label” the model uses to make predictions. Below is a deeper exploration of how labeling works and the challenges involved.
The Importance of Accurate Labeling
For supervised machine learning to work effectively, labeled data is required. Each training example in the dataset must have a corresponding label that tells the machine learning model the correct outcome or prediction. In seismic velocity model building from raw shot gathers using machine learning, this means that each shot gather must be linked to an accurate velocity model that describes the subsurface conditions. The model uses this labeled data to learn the relationship between the seismic data and the geological structures it represents. As the model trains, it refines its ability to predict velocity models for new, unseen shot gathers.
The accuracy of the labeled data is critical because the model’s performance is directly tied to the quality of the training data. If the labels are incorrect or inconsistent, the model will learn to make inaccurate predictions, undermining its utility in real-world applications.
Challenges in Labeling Seismic Data
- Manual Interpretation: Traditionally, labeling seismic data required manual interpretation by geophysicists or domain experts. This process involves analyzing raw shot gathers and then assigning a velocity model based on the geophysical characteristics observed. However, seismic data can be noisy, complex, and difficult to interpret, even for experienced professionals. Subjectivity in interpretation can lead to inconsistencies across labeled datasets, which can negatively affect model accuracy.
- Data Scarcity: In some cases, there may not be enough labeled data to train a machine learning model effectively. Generating labeled data manually for large datasets is labor-intensive and resource-heavy, making it difficult to scale. This scarcity of labeled data can limit the performance of machine learning models, especially in the case of more advanced models that require vast amounts of data to learn effectively.
Frequently Asked Questions (FAQs)
Q: How does machine learning improve velocity model building from raw shot gathers using machine learning?
A: Machine learning automates data analysis, reducing human error and accelerating the generation of more accurate velocity models.
Q: Is machine learning in seismic data reliable?
A: When properly trained and validated, machine learning models can be very reliable, especially when geophysical constraints are incorporated into the model to ensure accuracy.
Q: What challenges exist when using machine learning for velocity model building from raw shot gathers using machine learning?
A: Challenges include data scarcity, the risk of overfitting, and ensuring that machine learning models align with established geophysical principles.
Q: What preprocessing is required for seismic data before machine learning can be applied?
A: Preprocessing involves cleaning the data by removing noise, normalizing it, and extracting relevant features to ensure the data is suitable for analysis.
Q: Can machine learning replace traditional methods of velocity model building from raw shot gathers using machine learning?
A: While machine learning significantly enhances and speeds up the process, it is unlikely to fully replace traditional methods. Instead, it complements them by automating routine tasks and improving model accuracy.
Conclusion
Machine learning is revolutionizing the way velocity models are created from raw seismic data. By automating many of the complex tasks involved in data processing and interpretation, machine learning not only speeds up the velocity model creation process but also improves its accuracy. As the technology advances, machine learning promises to continue enhancing the efficiency and reliability of seismic data interpretation, allowing for better-informed decision-making in fields like oil and gas exploration and geotechnical engineering.
Stay Connected: Crisp Me





